

AMD RDNA 4 architektúra mélyreható merülés: A 64 CPU-s monolitikus kialakítás átfogó fejlesztésekkel a számítás, a média kódolás-dekódolás, a sugárkövetés és a mesterséges intelligencia terén

Az AMD felajánlott egy betekintést a CES 2025-ön az RDNA 4-ről, és megerősítette a Radeon RX 9070 XT és az RX 9070 érkezését, de a tényleges keynote során még egy futó megjegyzést sem tett az új architektúráról.
A vállalat azonban fenntartotta, hogy az RDNA 4-ről és az új Radeon GPU-król hamarosan több információ érkezik, és most itt vagyunk.
Ma az AMD lerántja a leplet az RDNA 4-ről és az új Radeon RX 9070 sorozatú GPU-król. Az RX 9070-es sorozat hivatalosan március 6-tól lesz kapható a kiskereskedelmi üzletekben, a teljesítményértékelések pedig egy nappal korábban landolnak.
AMD RDNA 4: Vissza a monolitikus kialakításhoz
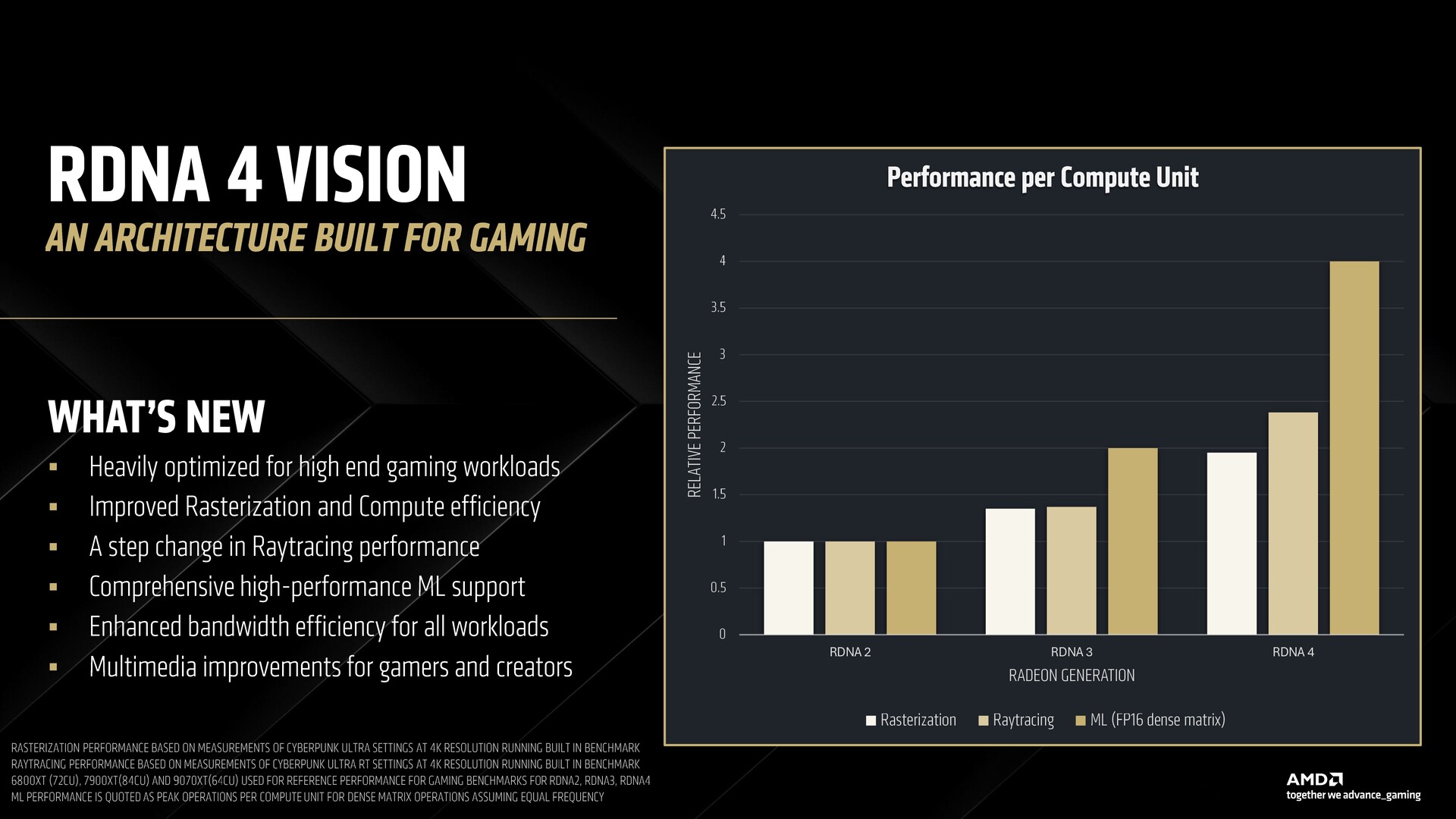
Az RDNA 4 az AMD által az RDNA 3-mal kitűzött célokra épül. Az AMD szerint az RDNA 4 a nehezebb játékmunkaterhelések kiszolgálására készült, a raszteres teljesítmény és a hatékonyság javítására összpontosítva.
Ezután ott vannak a ray tracing csővezetékek megszokott fejlesztései is, valamint az AI képességekre és a média kódolásra/dekódolásra való újbóli összpontosítás.
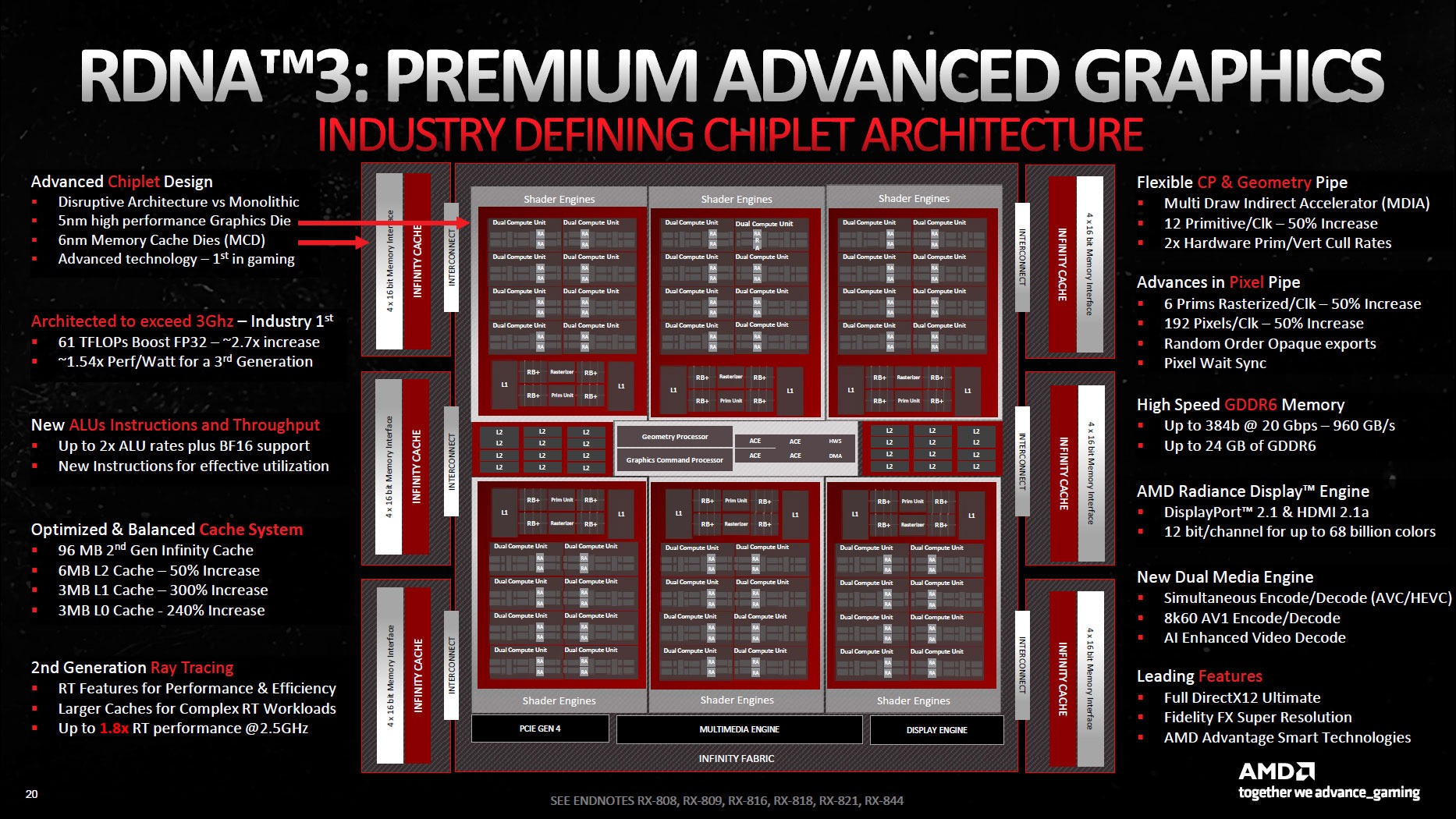
Az RDNA 3 a Ryzen processzorok által inspirált chiplet-dizájn megjelenését jelentette a GPU-k számára. Itt láthattuk a memória gyorsítótár-diék (MCD) és a grafikus számítási diék (GCD) szétválasztását.
Az RDNA 4-gyel azonban az AMD visszatér a hagyományos monolitikus kialakításhoz. Az alkatrészek lényegében ugyanazok, de nincsenek MCD-GCD összeköttetések, mivel a memória és a számítás immár közvetlenül az Infinity Cache segítségével kapcsolódik egymáshoz.
Az RDNA 4 GPU, jelen esetben a Radeon RX 9070 XT, négy shader motorral rendelkezik, egyenként nyolc munkacsoportos processzorral (WGP). Mindegyik WGP összesen nyolc számítási egységből (CU) áll, így összesen 64 CU-t tartalmaz.
Az AMD szerint az új számítási egységek minden eddiginél nagyobb teljesítményűek, lehetővé téve a továbbfejlesztett sugárkövetést, a kétszeres csúcsteljesítményt, a legújabb mátrixgyorsítási képességek támogatását szélesebb körű numerikus formátumtámogatással.
Az RDNA 4 CU újdonsága, amelyet már az Nvidia Ampere architektúrájának Tensor magjainál is láthattunk, a strukturált ritkaság támogatása, amely gyorsabb mátrixműveleteket tesz lehetővé, különösen olyan esetekben, amikor a súlyok közül sok nulla.
A memória alrendszerrel kapcsolatban is láthatunk fejlesztéseket. Az L2 gyorsítótár az RDNA 3-ban található 6 MB-ról 8 MB-ra nő az RDNA 4-ben, míg az Infinity Cache a 3. generációra frissül, de az RDNA 3-ban található 96 MB-ról 64 MB-ra csökken.
Az AMD az új generációval továbbra is a GDDR6 memóriára épít. Az RX 9070 XT és az RX 9070 egyaránt 384 bites, 16 GB-os GDDR6 memória interfészt kínál 20 Gbps-os órajelen, ami effektív 640 GB/s sávszélességet jelent. Ez jóval alacsonyabb, mint az RDNA 3 által kínált 960 GB/s sávszélesség, de az AMD szerint az RDNA 4 videomemória specifikációit gondosan választották ki, hogy támogassák a jelenlegi és jövőbeli címeket.

Továbbfejlesztett médiamotor és hardveres flip metering támogatás
A videokódolás volt az RDNA 3 egyik legnagyobb buktatója, és az AMD jelentős javulást ígér e tekintetben. A vállalat jelentős javulást ígér a H.264 és az AV1 kódolásban, valamint kevesebb blokkolási artefaktumot ugyanolyan adatmennyiség mellett.
A fejlesztések a videódekódolásra is kiterjednek, csökkentett energiafogyasztással és nagyobb teljesítménnyel az olyan formátumok dekódolása során, mint az AV1 és a VP9.
A Radiance Display Engine mostantól sokkal kevesebb energiát fogyaszt a kétmonitoros FreeSync-konfigurációkban. Szintén újdonság a hardveres flip queue támogatása a Windows Display Driver Model (WDDM) 3.0-ban a videolejátszáshoz.
Ez felszabadítja a CPU-erőforrásokat azáltal, hogy a képkockák ütemezését a GPU-ra terheli. Az Nvidia Blackwell GPU-kban található több képkocka generáló (MFG) technológia szintén a hardveres flip-kiosztásra támaszkodik.


Az RDNA 4 számítási egység megtekintése
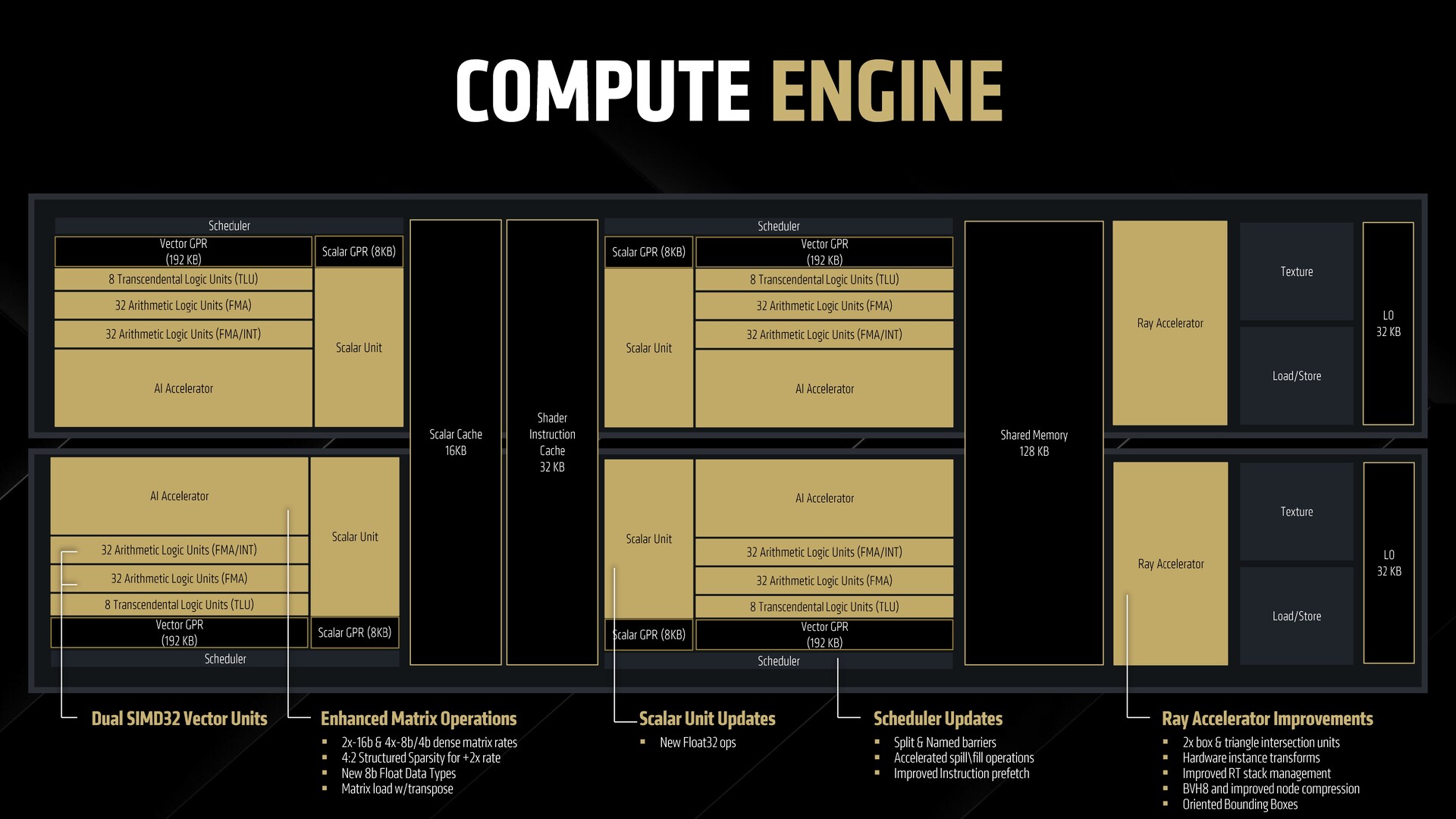
Kezdetben az RDNA 4 CU felépítése nem sokban különbözik az RDNA 3 esetében látottaktól, azonban a CU egyes összetevői teljesítmény- és hatékonyságjavulást mutatnak.
A WMMA (Wave Matrix Multiply Accumulate, hullámmátrix többszörözése-halmozás) műveleteket továbbfejlesztették az új hardver követelményeinek megfelelően. A skálázóegységek frissítéseket kapnak a Float32 műveletek kezelésére. Az ütemező képes a nagy számítási munkaterhelés felosztására és feldolgozására osztott és nevesített akadályokra.
Az AMD szerint az RDNA 4 úgy készült, hogy megfeleljen a fejlesztők által a mai játékokban használt új renderelési technikáknak. Míg a felskálázás divatos volt, a hatékony útvonalkövetés megköveteli az ML gyorsítást magának a renderelési folyamatnak a részeként, nem pedig utólagos megoldásként.

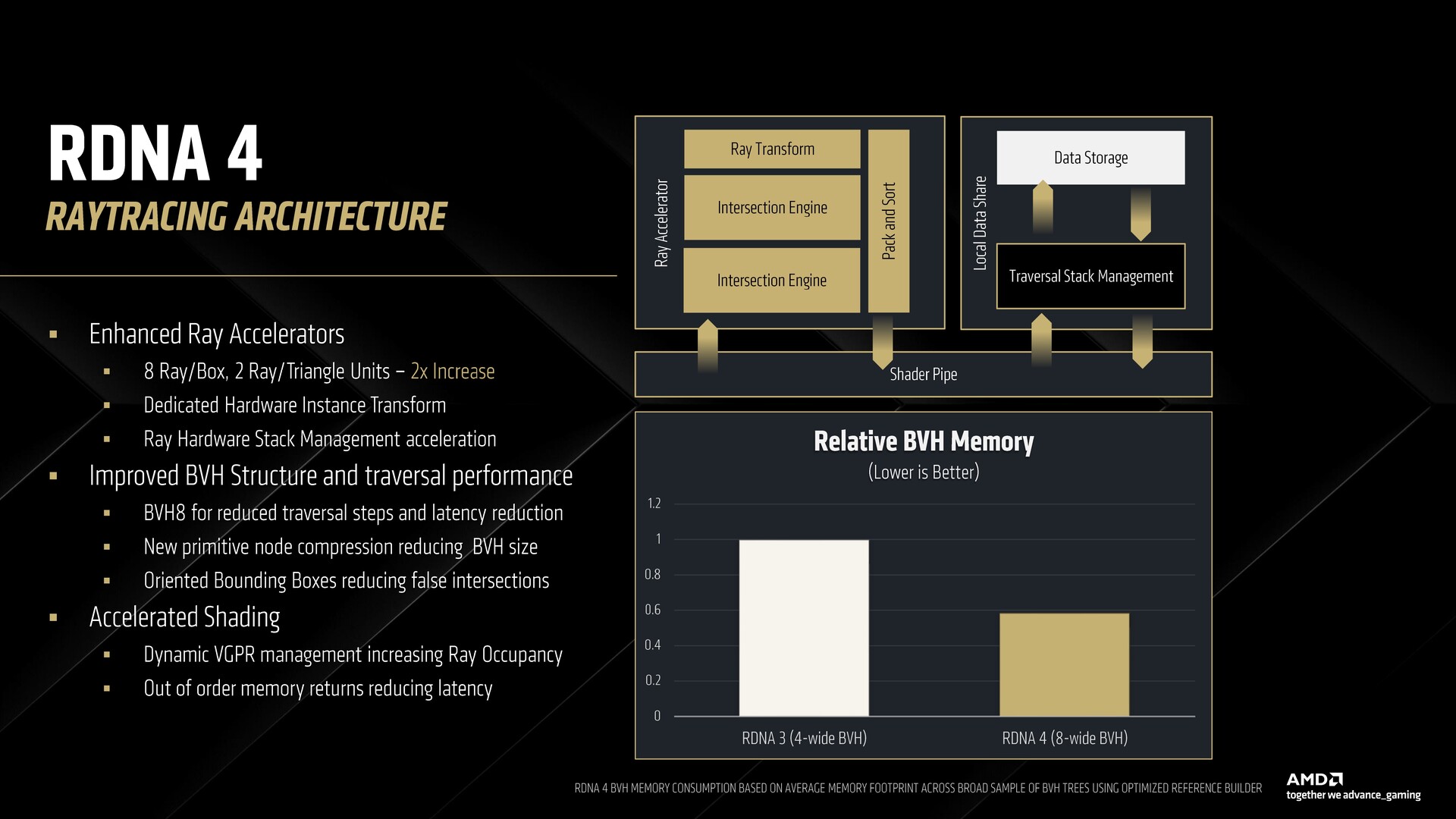
Sugárgyorsítók az RDNA 4-ben
Az RDNA 4 64 darab 3. generációs sugárgyorsítót kínál az RX 9070 XT-ben. A sugárgyorsító felépítése az RDNA 4-ben hasonló az RDNA 3-ban találhatóhoz, de tartalmaz egy további metszőmotort a 2x annyi sugárdoboz és sugárháromszög egységhez.
Van egy dedikált hardveres sugárátalakító is, amely megkönnyíti a shader utasítások használatát a feladat elvégzéséhez, így minimalizálva a sugárátjárási overheadet. Az egyes kettős CU-kban található 128 KB memória segít a ray stack tárolásában a hatékony push és sort művelet érdekében.
Az RDNA 4 bevezeti az orientált határoló dobozok (OBB) koncepcióját, amely a BVH határoló dobozokat a geometriához igazítja, ezáltal minimalizálva a hamis pozitív sugárinterakciókat az egyébként csak üres térben lévő dobozban. Az AMD szerint ez a megközelítés akár 10%-kal is javíthatja a sugarak áthaladásának teljesítményét.
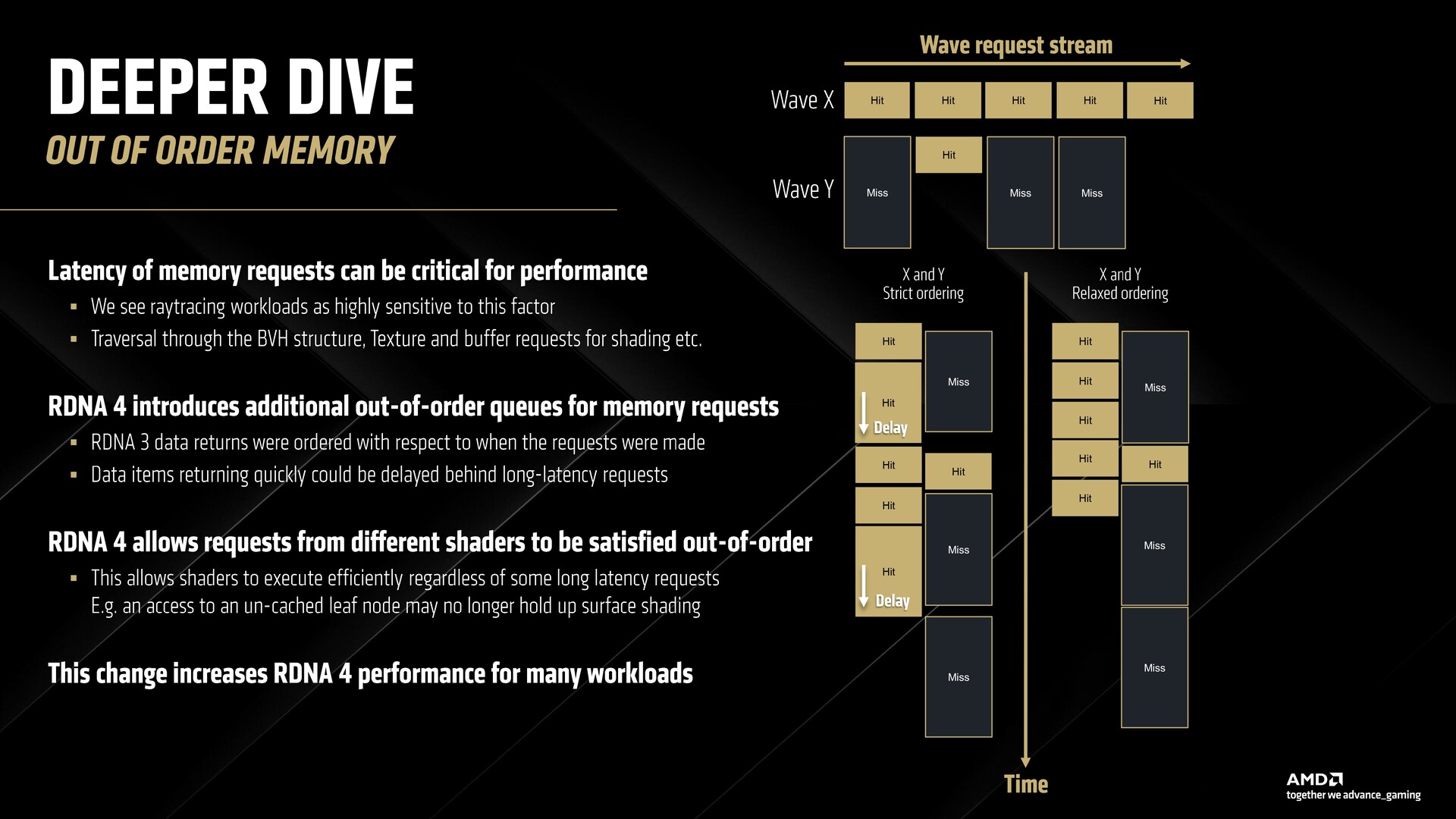
Szintén újdonság ezúttal a lazított, sorrenden kívüli memóriaigénylések támogatása, amely hatékonyan csökkenti a várakozási időt a magas szintű gyorsítótárat korábban elszalasztott hullámok esetében. Ez nemcsak a sugárkövetést, hanem más munkaterhelést is javítja.
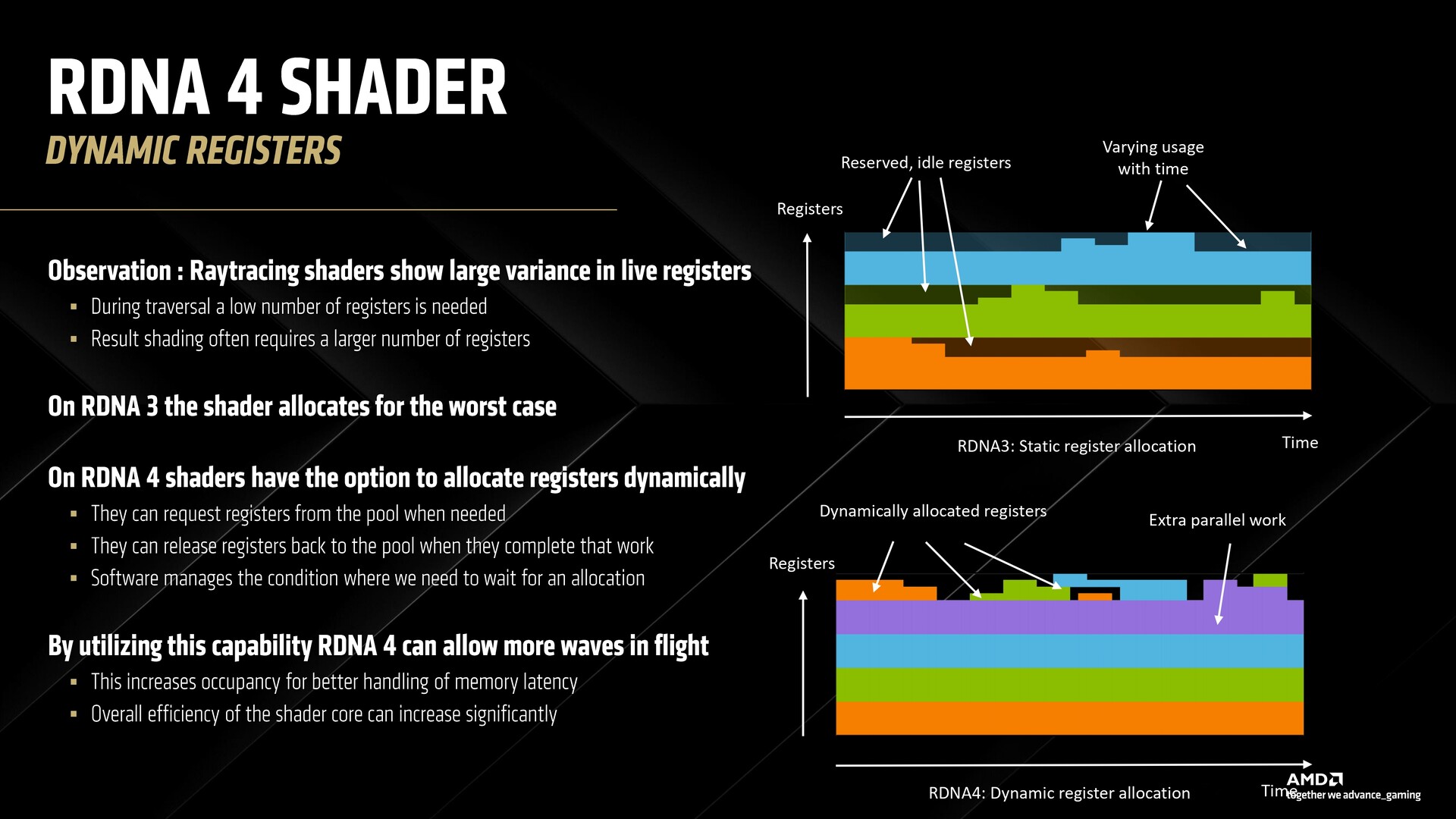
Az RDNA 4-ben a shaderek dinamikusan tudnak regisztereket kiosztani, ami lehetővé teszi több hullám befogadását repülés közben, javított memóriakésleltetéssel.


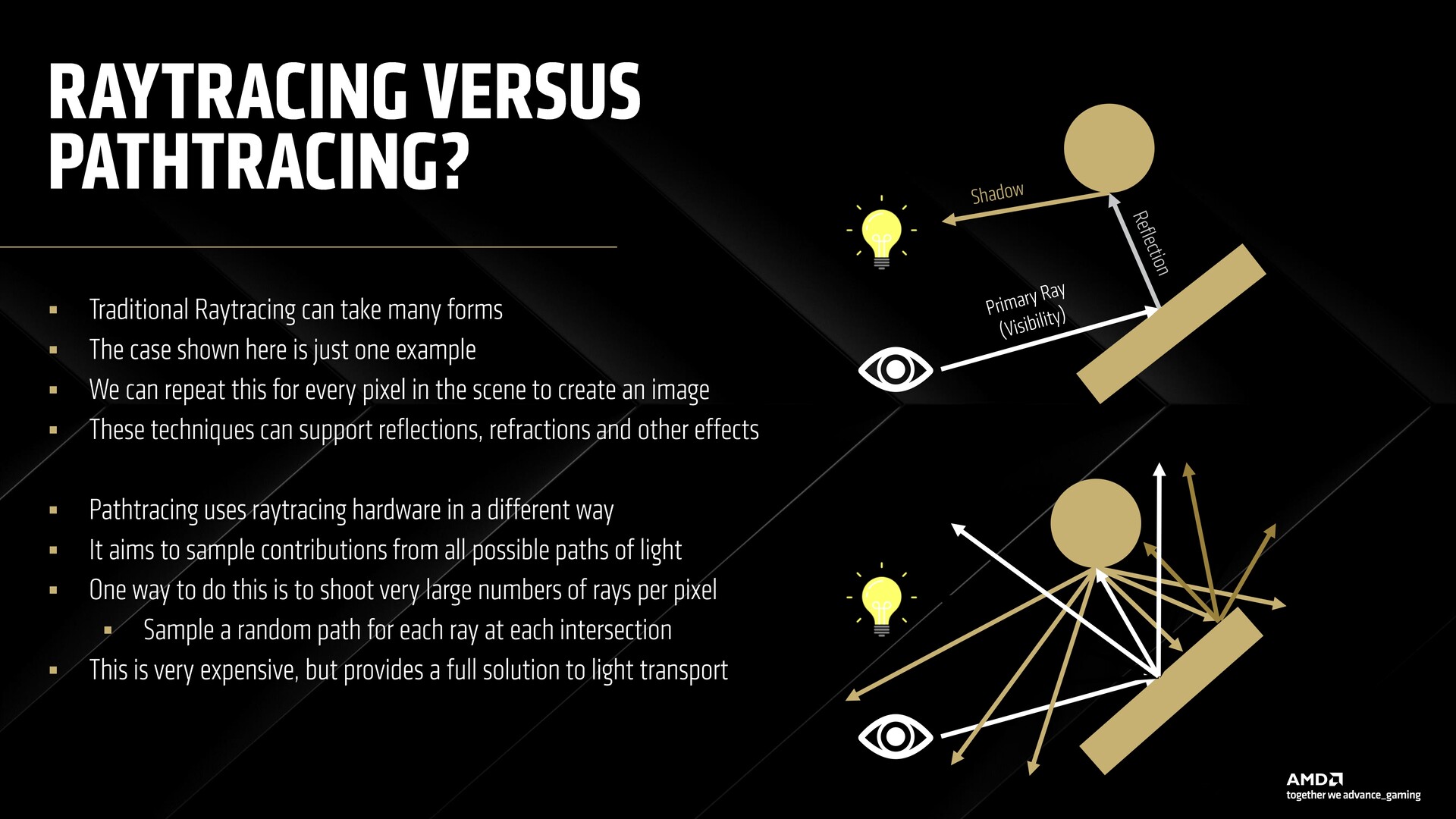
Útvonalkövetés az RDNA 4 segítségével
Az AMD kártyák általában véve küszködtek a sugárkövetéssel, így az útvonalkövetés még a csúcskategóriás RDNA 3 kártyák esetében is kizártnak tűnt. Az RDNA 4 célja, hogy ezen változtasson a neurális sugárzási gyorsítótárolás támogatásával, valamint egy új neurális szupermintázási és denoising modellel.
Az AMD még nem közölt pontos teljesítményszámokat az útvonalkövetést támogató címekhez, de a kártyák felülvizsgálata során kaphatunk egy kis ízelítőt.




Radeon és Instinct rendszerekre épülő AI képességek
Az AMD szerint az RDNA 4 dedikált matematikai csővezetékeket tartalmaz az ML gyorsításhoz, amelyek a szűkebb adattípusok nagy teljesítményére összpontosítanak. Az RDNA 4 újdonsága az FP8 és BF8 támogatása a nagy teljesítményű, nagy pontosságú következtetésekhez.
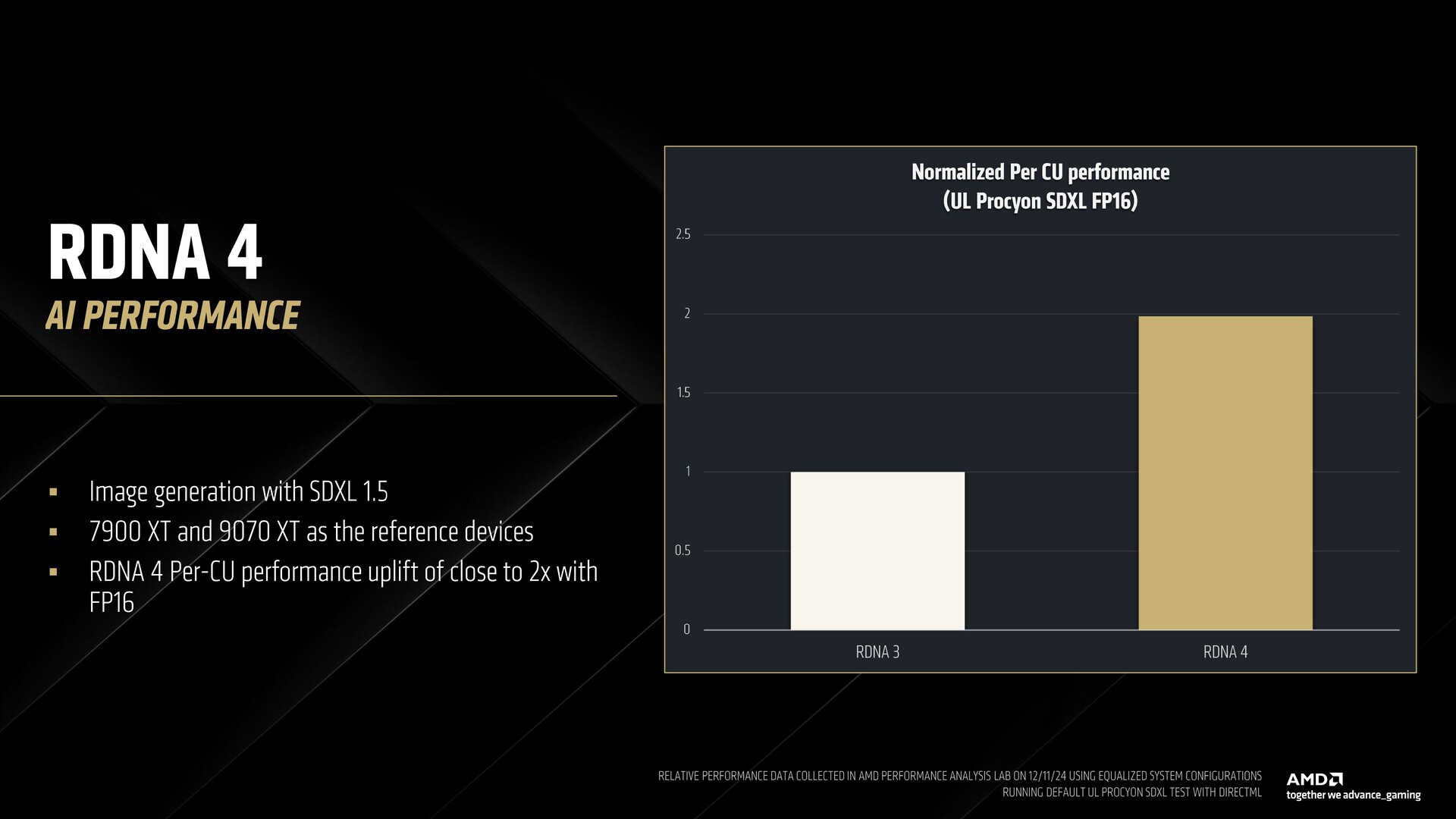
Az SDXL 1.5 képgenerálást demonstrálva az AMD bemutatta, hogy az RDNA 4 alapú Radeon RX 9070 XT kétszer akkora FP16 teljesítményt nyújt CU-nként, mint az RDNA 3 alapú RX 7900 XT.
Az RDNA 4 új AI-képességeit kihasználva az FSR 4, amely egy AMD GPU-kon képzett végponttól végpontig tartó csővezeték. Az FSR 4 az FP8-at használja a sávszélesség, a teljesítmény és az energia optimális kihasználása érdekében.
Az AMD akár 3,7x fps javulást mutatott ki az FSR 4 segítségével, amikor a képkocka interpolációval és a Radeon Anti-Laggal kombinálták, miközben a magas képminőség megmaradt.



Forrás(ok)
AMD sajtóközlemény










