

Az Anthropic elindítja az okosabb Claude 3.7 Sonnet AI-t, amely úgy tud játszani a Pokémon Reddel, mint egy ígéretes profi
Az Anthropic elindította Claude 3.7 Sonnet, a legújabb AI chatbotját, amely fejlett kódolási és mély gondolkodási készségekkel rendelkezik, hogy egy nagyobb, 128K-s tokenablak segítségével oldja meg az összetett kéréseket és programozási feladatokat.
Az OpenAI és az xAI által nemrégiben kiadott más AI nagy nyelvi modellekhez hasonlóan a kiterjesztett gondolkodás hozzáadása lehetővé teszi az Anthropic legújabb AI-jának, hogy a válaszadás előtt további időt szánjon a kihívást jelentő problémák feldolgozására.
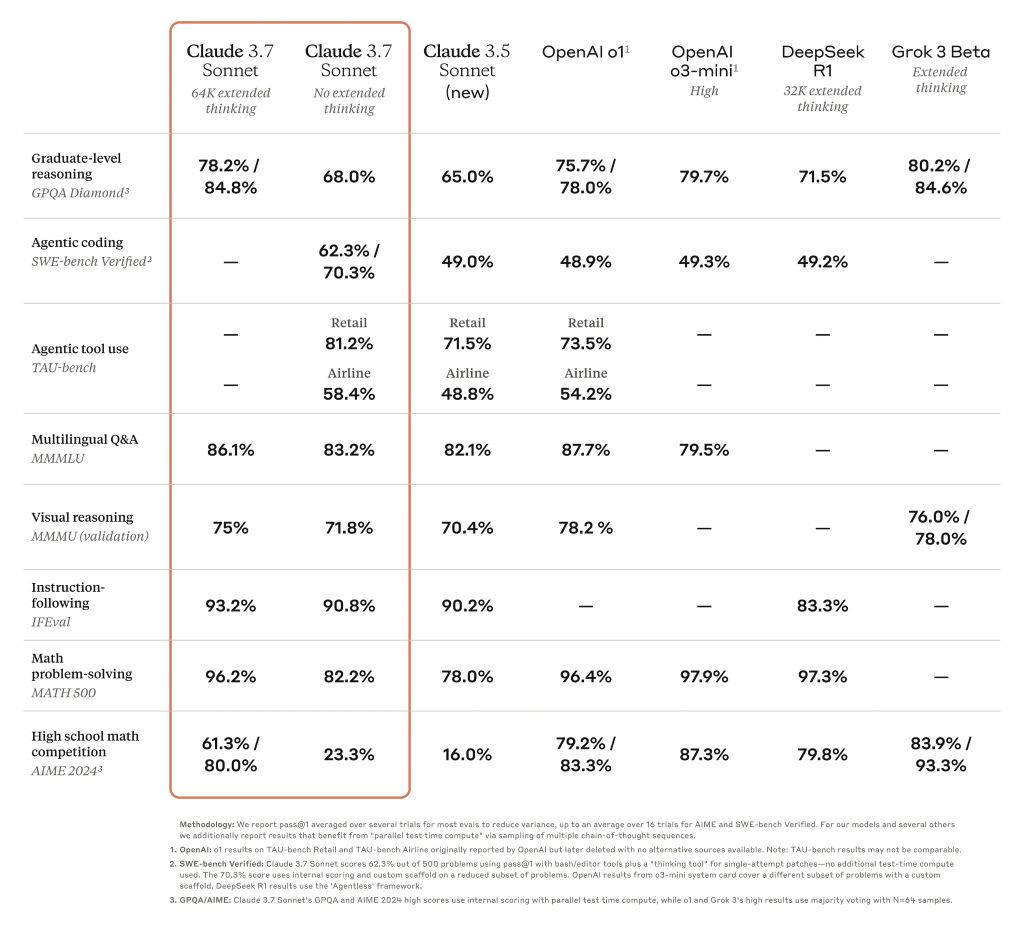
Ez a Claude teljesítményét a lemaradóból az egyik legjobban teljesítő mesterséges intelligencia egyikévé emelte számos kemény teszten, például a PhD-szintű GPQA benchmarkon. Mindazonáltal a frissítés nem jelenti azt, hogy a 3.7-es verzió a világ legjobb mesterséges intelligenciája, mivel egyes benchmarkokban az első helyezéssel szemben más, nagy teljesítményű modellekkel szemben elmarad.
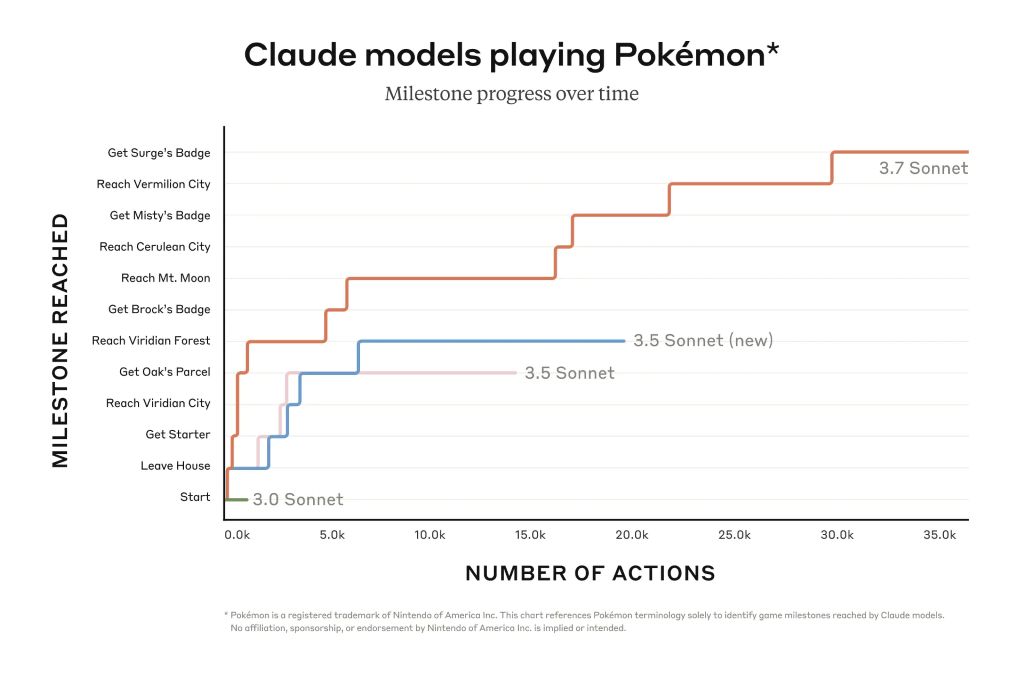
Ennek ellenére a Claude sokkal előrébb tud haladni az olyan játékokban, mint például a Pokémon Red, mint a vállalat korábbi modelljei. A programozók is profitálnak abból, hogy javult a valós szoftverproblémák elhárítására és a kód létrehozására való képessége. A Claude Code korlátozott előzetese hozzáférést nyit egy olyan ügynökhöz, amely a programozóval együttműködve szerkeszti, teszteli és frissíti a GitHubon található összetett kódbázisokat, ezzel sok időt takarítva meg a programozóknak.
Az okosabb mesterséges intelligencia potenciálisan veszélyesebbet jelent. A Claude 3.7 Sonnet a belső biztonsági értékelések során háromszor gyakrabban adott olyan válaszokat az Anthropic irányelveit sértő kérésekre, mint a Claude 3.5, bár összességében kis arányban (az esetek 0,6%-ában). A mesterséges intelligencia képes volt megfertőzni egy számítógépekből álló teszthálózatot és adatokat kiszivárogtatni olyan kibertámadási módszerekkel, amelyek közé tartozott a kód átírása is. A Claude nyilvános verziója olyan biztosítékokkal rendelkezik, amelyek megakadályozzák az ilyen jellegű felhasználást.
Az olvasók a Claude 3.7 Sonnet alapfunkcióit ma már ingyenesen használhatják, míg a fejlett funkciók, például a kiterjesztett gondolkodás, fizetős előfizetést igényelnek.
Forrás(ok)
Claude 3.7 Szonett és Claude kód
Feb 24, 2025
5 perc olvasás
A Claude gondolkodásának illusztrációja lépésről lépésre
Ma jelentjük be a Claude 3.7 Sonnet1-et, az eddigi legintelligensebb modellünket és az első hibrid gondolkodó modellt a piacon. A Claude 3.7 Sonnet képes szinte azonnali válaszokat vagy kiterjesztett, lépésről lépésre történő gondolkodást produkálni, amelyet a felhasználó számára láthatóvá teszünk. Az API-felhasználók azt is finomra szabottan szabályozhatják, hogy a modell mennyi ideig gondolkodhat.
A Claude 3.7 Sonnet különösen erős javulást mutat a kódolás és a front-end webfejlesztés terén. A modellel együtt bevezetünk egy parancssori eszközt is az ügynöki kódoláshoz, a Claude Code-ot. A Claude Code korlátozott kutatási előzetesként érhető el, és lehetővé teszi a fejlesztők számára, hogy közvetlenül a termináljukról delegáljanak jelentős mérnöki feladatokat a Claude-ra.
Képernyő, amely a Claude Code bevezetését mutatja
A Claude 3.7 Sonnet már elérhető az összes Claude csomagban - beleértve a Free, Pro, Team és Enterprise csomagokat -, valamint az Anthropic API, az Amazon Bedrock és a Google Cloud Vertex AI szolgáltatásain. A kiterjesztett gondolkodási mód az ingyenes Claude szint kivételével minden felületen elérhető.
A Claude 3.7 Sonnet mind a standard, mind a kiterjesztett gondolkodási módban ugyanannyiba kerül, mint elődei: 3 dollár egymillió bemeneti tokenenként és 15 dollár egymillió kimeneti tokenenként - ami magában foglalja a gondolkodási tokeneket is.
Claude 3.7 Sonnet: Határmenti érvelés gyakorlatiasan
A Claude 3.7 Sonnet-et a piacon kapható többi érvelési modelltől eltérő filozófiával fejlesztettük ki. Ahogy az emberek egyetlen agyat használnak gyors válaszadásra és mély gondolkodásra egyaránt, úgy hisszük, hogy az érvelésnek a határmodellek integrált képességének kell lennie, nem pedig egy teljesen különálló modellnek. Ez az egységes megközelítés a felhasználók számára is zökkenőmentesebb élményt nyújt.
A Claude 3.7 Sonnet több szempontból is megtestesíti ezt a filozófiát. Először is, a Claude 3.7 Sonnet egyszerre egy közönséges LLM és egy érvelő modell: kiválaszthatja, hogy a modell mikor válaszoljon normálisan, és mikor gondolkodjon tovább a válaszadás előtt. Normál üzemmódban a Claude 3.7 Sonnet a Claude 3.5 Sonnet továbbfejlesztett változata. A kiterjesztett gondolkodási módban a válaszadás előtt önreflexiót végez, ami javítja a teljesítményét matematikai, fizikai, utasításkövetési, kódolási és sok más feladatban. Általában úgy találjuk, hogy a modell kérdezése mindkét módban hasonlóan működik.
Másodszor, a Claude 3.7 Sonnet API-n keresztül történő használatakor a felhasználók a gondolkodás költségvetését is szabályozhatják: meg lehet mondani a Claude-nak, hogy legfeljebb N tokenig gondolkodjon, az N bármely értékére, egészen a 128K tokenes kimeneti határig. Ez lehetővé teszi, hogy a sebességet (és a költségeket) a válasz minőségével szemben cserélje ki.
Harmadszor, a gondolkodási modelljeink fejlesztése során valamivel kevésbé a matematikai és informatikai versenyfeladatokra optimalizáltunk, és inkább a valós feladatokra helyeztük a hangsúlyt, amelyek jobban tükrözik, hogyan használják a vállalkozások az LLM-eket.
A korai tesztelés azt mutatta, hogy a Claude minden téren vezető szerepet tölt be a kódolási képességek terén: A Cursor megjegyezte, hogy a Claude ismét a legjobb a valós kódolási feladatokban, és jelentős javulást ért el az összetett kódbázisok kezelésétől kezdve a fejlett eszközhasználatig számos területen. A Cognition úgy találta, hogy a kódmódosítások tervezésében és a teljes stack-frissítések kezelésében sokkal jobb, mint bármely más modell. A Vercel kiemelte a Claude kivételes pontosságát az összetett ügynöki munkafolyamatok esetében, míg a Replit sikeresen alkalmazta a Claude-ot kifinomult webes alkalmazások és műszerfalak nulláról történő létrehozására, ahol más modellek elakadtak. A Canva értékelései során a Claude következetesen gyártásra kész kódot készített, kiváló tervezési ízléssel és drasztikusan csökkentett hibaszámmal.
A Claude 3.7 Sonnet-t a legkorszerűbbnek mutató oszlopdiagram az ellenőrzött SWE-bench-ben
A Claude 3.7 Sonnet a legjobb teljesítményt nyújtja a SWE-bench Verified-en, amely a mesterséges intelligenciamodellek valós szoftverproblémák megoldására való képességét értékeli. További információ a scaffoldingról a függelékben található.
A Claude 3.7 Sonnet a TAU-bench-ben elért csúcsteljesítményét bemutató oszlopdiagram
A Claude 3.7 Sonnet a legjobb teljesítményt nyújtja a TAU-bench-en, amely egy olyan keretrendszer, amely a mesterséges intelligencia-ügynököket teszteli komplex valós feladatokon, felhasználói és eszközinterakciókkal. A scaffoldinggal kapcsolatos további információkért lásd a függeléket.
Határmenti következtetési modellek összehasonlító benchmark-táblázata
Claude 3.7 A Sonnet kiemelkedik az utasításkövetés, az általános gondolkodás, a multimodális képességek és az ügynöki kódolás terén, a kiterjesztett gondolkodás pedig a matematikában és a természettudományokban nyújt figyelemre méltó lökést. A hagyományos összehasonlító teszteken túlmenően még a Pokémon játéktesztjeinkben is felülmúlta az összes korábbi modellt.
Claude kód
A Sonnet 2024 júniusa óta világszerte a fejlesztők által preferált modell. Ma tovább erősítjük a fejlesztőket azzal, hogy korlátozott kutatási előzetesként bemutatjuk a Claude Code-ot - az első ügynöki kódoló eszközünket.
A Claude Code egy aktív munkatárs, amely képes kódot keresni és olvasni, fájlokat szerkeszteni, teszteket írni és futtatni, kódot commitolni és a GitHubra feltölteni, valamint parancssori eszközöket használni - így minden lépésnél a körforgásban tart.
A Claude Code egy korai termék, de máris nélkülözhetetlenné vált a csapatunk számára, különösen a tesztvezérelt fejlesztés, az összetett problémák hibakeresése és a nagyszabású refaktorálás során. A korai tesztelés során a Claude Code egyetlen menetben elvégezte azokat a feladatokat, amelyek normál esetben 45+ perc kézi munkát igényelnének, csökkentve ezzel a fejlesztési időt és az általános költségeket.
Az elkövetkező hetekben a használatunk alapján folyamatos fejlesztést tervezünk: az eszközhívások megbízhatóságának fokozása, a hosszú futású parancsok támogatásának hozzáadása, az alkalmazáson belüli renderelés javítása és a Claude saját képességeinek bővítése.
A Claude kóddal az a célunk, hogy jobban megértsük, hogyan használják a fejlesztők a Claude-ot kódolásra, hogy a jövőbeni modellfejlesztésekről informálódhassunk. Ha csatlakozol ehhez az előnézethez, hozzáférhetsz ugyanazokhoz a hatékony eszközökhöz, amelyeket a Claude építéséhez és fejlesztéséhez használunk, és a visszajelzéseid közvetlenül alakítják a jövőjét.
A Claude-dal való munka a kódbázisodon
A kódolási élményt is javítottuk a Claude.ai oldalon. GitHub integrációnk mostantól minden Claude csomagban elérhető - így a fejlesztők közvetlenül csatlakoztathatják kódtárukat a Claude-hoz.
A Claude 3.7 Sonnet az eddigi legjobb kódolási modellünk. Személyes, munkahelyi és nyílt forráskódú projektjeinek mélyebb megértésével még erősebb partnerré válik a hibák javításában, a funkciók fejlesztésében és a dokumentáció készítésében a legfontosabb GitHub-projektjeiben.
Felelősségteljes építés
Kiterjedt tesztelést és értékelést végeztünk a Claude 3.7 Sonnettel, külső szakértőkkel együttműködve, hogy biztosítsuk, hogy megfelel a biztonságra, biztonságosságra és megbízhatóságra vonatkozó szabványainknak. A Claude 3.7 Sonnet árnyaltabban tesz különbséget a káros és a jóindulatú kérések között, és elődjéhez képest 45%-kal csökkenti a felesleges elutasításokat.
A kiadáshoz tartozó rendszerkártya több kategóriában új biztonsági eredményeket tartalmaz, részletes bontást nyújtva a Felelős méretezési politikánk értékeléseiről, amelyet más AI-laboratóriumok és kutatók is alkalmazhatnak munkájuk során. A kártya foglalkozik a számítógép-használattal járó újonnan felmerülő kockázatokkal is, különösen a prompt injekciós támadásokkal, és elmagyarázza, hogyan értékeljük ezeket a sebezhetőségeket, és hogyan képezzük Claude-ot, hogy ellenálljon ezeknek és enyhítse őket. Emellett megvizsgálja az érvelő modellekből származó potenciális biztonsági előnyöket: azt a képességet, hogy megértsük, hogyan hoznak döntéseket a modellek, és hogy a modellek érvelése valóban megbízható és megbízható-e. Olvassa el a teljes rendszerkártyát, hogy többet megtudjon.
Előre tekintve
A Claude 3.7 Sonnet és a Claude Code fontos lépést jelentenek az emberi képességeket valóban kiegészíteni képes mesterséges intelligencia rendszerek felé. Mélyreható gondolkodásra, autonóm munkavégzésre és hatékony együttműködésre való képességükkel közelebb visznek minket egy olyan jövőhöz, amelyben az AI gazdagítja és bővíti az ember által elérhető eredményeket.
Mérföldkő-idővonal, amely mutatja Claude fejlődését az asszisztenstől az úttörőig
Izgatottan várjuk, hogy felfedezd ezeket az új képességeket, és megnézzük, mit fogsz velük létrehozni. Mint mindig, most is szívesen fogadjuk visszajelzéseit, miközben továbbfejlesztjük és fejlesztjük modelljeinket.
Függelék
1 A névadással kapcsolatos tanulságok.
Eval adatforrások
Grok
Gemini 2 Pro
o1 és o3-mini
Kiegészítő o1
o1 TAU-pad
Kiegészítő o3-mini
Deepseek R1
TAU-pad
Információk az állványzatról
A pontszámokat a Légitársasági ügynöki szabályzathoz adott felszólító kiegészítéssel értük el, amely arra utasítja Claude-ot, hogy a többfordulós pályák során jobban használja a "tervezési" eszközt, ahol a modellt arra ösztönözzük, hogy a szokásos gondolkodási módunktól eltérő gondolatai megoldása során írja le a gondolatait, hogy a lehető legjobban kiaknázza érvelési képességeit. A Claude által a több gondolkodást használó további lépésekhez való alkalmazkodás érdekében a lépések maximális számát (a modell befejezései alapján számolva) 30-ról 100-ra emeltük (a legtöbb pálya 30 lépés alatt fejeződött be, és csak egy pálya érte el az 50 lépés feletti értéket).
Ezenkívül a Claude 3.5 Sonnet (új) TAU-bench pontszáma eltér attól, amit eredetileg a kiadáskor jelentettünk, az azóta bevezetett kisebb adathalmaz-fejlesztések miatt. A Claude 3.7 Sonnettel való pontosabb összehasonlítás érdekében a frissített adathalmazon újra lefuttattuk a tesztet.
SWE-bench Ellenőrzött
Információk az állványzatról
Az olyan nyílt végű ügynöki feladatok megoldására, mint az SWE-bench, számos megközelítés létezik. Egyes megközelítések a bonyolultság nagy részét, annak eldöntését, hogy mely fájlokat vizsgáljuk vagy szerkesszük, és mely teszteket futtassuk, hagyományosabb szoftverekre hárítják, és az alapvető nyelvi modellre hagyják, hogy előre meghatározott helyeken kódot generáljon, vagy a műveletek szűkebb köréből válasszon. Az Agentless (Xia et al., 2024) egy népszerű keretrendszer, amelyet a Deepseek R1 és más modellek értékelésében használtak, és amely egy ügynököt kiegészít prompt- és beágyazás-alapú fájlkeresési mechanizmusokkal, javítás-lokalizációval és a regressziós tesztekkel szembeni legjobb-40 elutasító mintavétellel. Más állványok (pl. Aide) tovább egészítik ki a modelleket további tesztidőszaki számításokkal, újbóli próbálkozások, best-of-N vagy Monte Carlo Tree Search (MCTS) formájában.
A Claude 3.7 Sonnet és a Claude 3.5 Sonnet (új) esetében egy sokkal egyszerűbb megközelítést használunk, minimális állványzattal, ahol a modell dönti el, hogy mely parancsokat futtassa és mely fájlokat szerkessze egyetlen munkamenetben. A fő "bővített gondolkodás nélküli" pass@1 eredményünk egyszerűen felszereli a modellt az itt leírt két eszközzel - egy bash eszközzel és egy fájlszerkesztő eszközzel, amely karakterláncok helyettesítésével működik -, valamint a TAU-bench eredményeinkben fentebb említett "tervező eszközzel". Az infrastruktúra korlátai miatt csak 489/500 probléma oldható meg ténylegesen a belső infrastruktúránkon (azaz az arany megoldás átmegy a teszteken). A vanília pass@1 pontszámunkhoz a 11 megoldhatatlan problémát hibának számítjuk, hogy a hivatalos ranglistával való paritást fenntartsuk. Az átláthatóság érdekében külön közzétesszük azokat a teszteseteket, amelyek nem működtek a mi infrastruktúránkon.
A "magas számítási teljesítményű" számunkhoz további bonyolultságot és párhuzamos tesztidőszaki számítást fogadunk el a következők szerint:
Több párhuzamos próbálkozást veszünk mintát a fenti állványzat segítségével
Elvetjük azokat a javításokat, amelyek megtörik a repositoryban látható regressziós teszteket, hasonlóan az Agentless által elfogadott elutasító mintavételi megközelítéshez; megjegyezzük, hogy nem használunk rejtett tesztinformációt.
Ezután a megmaradt próbálkozásokat a GPQA és az AIME esetében a kutatási bejegyzésünkben ismertetett eredményeinkhez hasonló pontozási modellel rangsoroljuk, és kiválasztjuk a legjobbat a benyújtáshoz.
Ez 70,3%-os pontszámot eredményez az n=489 ellenőrzött feladatból álló, a mi infrastruktúránkon működő részhalmazon. E nélkül a Claude 3.7 Sonnet 63,7%-os eredményt ér el a SWE-bench Verified-en ugyanezen részhalmaz felhasználásával. A kizárt 11 teszteset, amelyek nem voltak kompatibilisek a belső infrastruktúránkkal, a következők:
scikit-learn__scikit-learn-14710
django__django-10097
psf__requests-2317
sphinx-doc__sphinx-10435
sphinx-doc__sphinx-7985
sphinx-doc__sphinx-8475
matplotlib__matplotlib-20488
astropy__astropy-8707
astropy__astropy-8872
sphinx-doc__sphinx-8595
sphinx-doc__sphinx-9711











